What PriceBench Does
PriceBench is an advanced AI pricing model that analyzes product descriptions, features, and specifications to accurately predict retail prices from $1 to $999. Trained on 400,000+ curated Amazon products using state-of-the-art QLoRA techniques on Meta-Llama-3.1-8B.
Applications include e-commerce pricing optimization, market research, inventory valuation, and competitive analysis. PriceBench significantly outperforms traditional regression models and statistical methods, delivering accuracy on par with expensive frontier AI models at a fraction of the cost.
About PriceBench
Complete code files for data curation and training can be found in the GitHub Repository.
📚 Interactive Notebooks
Main Google Colab of Training: Training Notebook
Main Google Colab of Benchmarking/Results: Results & Benchmarking Notebook
Training Dataset (train.pkl): Download train.pkl file (too large for GitHub)
Both notebook files are also available on GitHub as .ipynb files
📊 Data Curation Process
1. Dataset Selection and Initial Loading
The training process began with the Amazon Reviews 2023 dataset from Hugging Face, specifically focusing on multiple product categories including:
- Automotive
- Electronics
- Office Products
- Tools and Home Improvement
- Cell Phones and Accessories
- Toys and Games
- Appliances
- Musical Instruments
2. Data Filtering and Quality Control
A rigorous filtering process was implemented to ensure high-quality training data:
- Price Range: Only products with prices between $0.50 and $999.49 were included
- Content Requirements: Products needed minimum 300 characters of description content
- Token Limits: Text was truncated to 150-160 tokens to maintain consistency
- Data Cleaning: Removal of irrelevant metadata, product codes, and standardization of text formats
3. Text Processing and Tokenization
The Item class handled sophisticated text preprocessing:
- Combination of product title, description, features, and technical details
- Removal of unnecessary characters, brackets, and product-specific codes
- Tokenization using Meta-Llama-3.1-8B tokenizer for consistency with the base model
- Smart truncation to maintain semantic meaning within token limits
4. Dataset Balancing and Sampling
To create a well-balanced training dataset:
- Price Distribution: Implemented weighted sampling to reduce bias toward low-priced items
- Category Balance: Applied category-specific weights to prevent over-representation of certain product types
- Final Dataset: Curated 402,000 high-quality product entries with balanced price distribution (average ~$125)
5. Prompt Engineering
Each training example was formatted with a consistent structure:
- Question: "How much does this cost to the nearest dollar?"
- Product Information: Cleaned and tokenized product details
- Answer Format: "Price is $XXX.00" for consistent completion learning
🚀 Model Training Process
6. Base Model Selection
Meta-Llama-3.1-8B was chosen as the foundation model due to its:
- Excellent numerical reasoning capabilities
- Efficient tokenization of numbers (1-999 map to single tokens)
- Strong instruction-following abilities
- Optimal balance between performance and computational requirements
7. Quantization and Memory Optimization
To enable efficient training on consumer hardware:
- 4-bit Quantization: Used BitsAndBytesConfig with NF4 quantization
- Double Quantization: Applied additional compression for memory efficiency
- Memory Footprint: Reduced model size to approximately 4.5GB
8. QLoRA Fine-tuning Configuration
Parameter-efficient fine-tuning was implemented using QLoRA:
- LoRA Rank (r): 32 for optimal parameter efficiency
- LoRA Alpha: 64 for scaling factor
- Target Modules: Applied to attention layers (q_proj, k_proj, v_proj, o_proj)
- Dropout: 0.1 to prevent overfitting
9. Training Hyperparameters
Carefully tuned training configuration:
- Learning Rate: 1e-4 with cosine scheduling
- Batch Size: 1 with gradient accumulation
- Epochs: 1 (sufficient due to large dataset size)
- Optimizer: Paged AdamW 32-bit for memory efficiency
- Sequence Length: 182 tokens maximum
10. Specialized Data Collation
Used DataCollatorForCompletionOnlyLM to:
- Focus loss calculation only on price predictions
- Ignore input tokens during loss computation
- Enable efficient completion-based learning
11. Training Infrastructure
Professional training setup included:
- Platform: Google Colab with GPU acceleration
- Monitoring: Weights & Biases integration for experiment tracking
- Version Control: Automatic model versioning and Hub integration
- Checkpointing: Regular saves every 50 steps for reliability
12. Model Evaluation and Testing
Comprehensive evaluation framework with custom Tester class:
- Error Metrics: Mean Absolute Error (MAE) and Root Mean Square Logarithmic Error (RMSLE)
- Color-coded Results: Green (excellent), Orange (good), Red (needs improvement)
- Scatter Plot Analysis: Visual comparison between predictions and ground truth
- Hit Rate Calculation: Percentage of predictions within acceptable error margins
The result is a highly specialized pricing model that achieves professional-grade accuracy while maintaining computational efficiency and cost-effectiveness.
🏆 Performance Benchmarking Results
PriceBench was evaluated against a comprehensive range of models, from traditional machine learning approaches to cutting-edge frontier AI models. The results demonstrate PriceBench's exceptional performance across all categories.
📊 Summary of Results (Average Error in USD)
PriceBench (QLoRA Fine-tuned)
Our specialized model
GPT-4o
OpenAI's flagship model
GPT-4 Mini
OpenAI's efficient model
🤖 AI Language Models
Comparison with state-of-the-art AI models shows PriceBench's competitive edge:
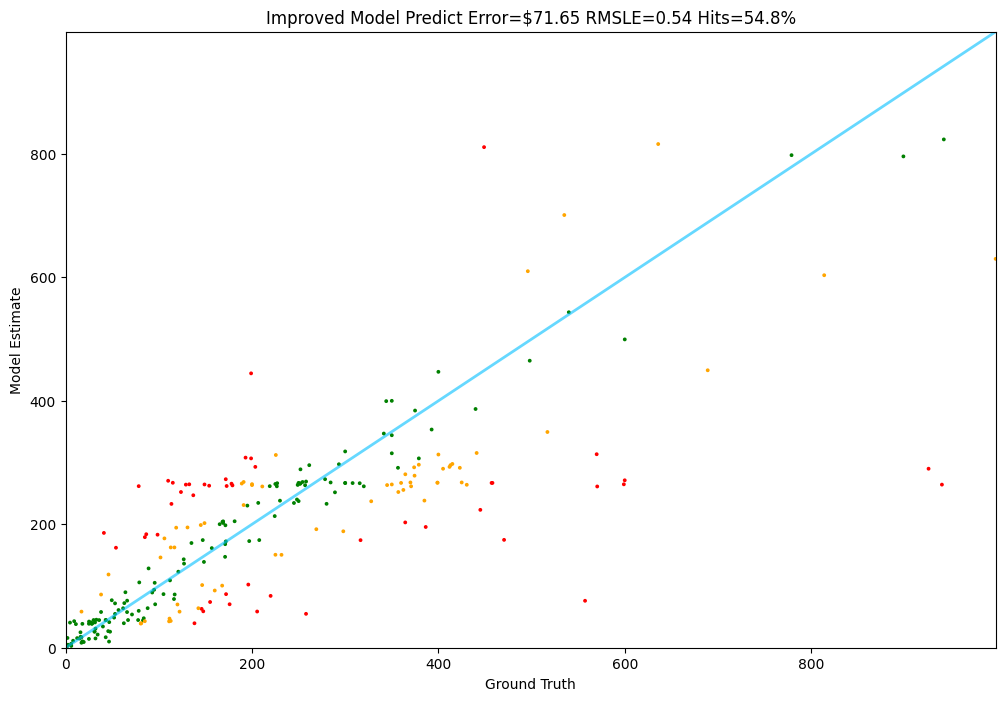
🏆 PriceBench (Meta-Llama-3.1-8B + QLoRA)
Our fine-tuned model achieves the best performance while being significantly more cost-effective than frontier models.
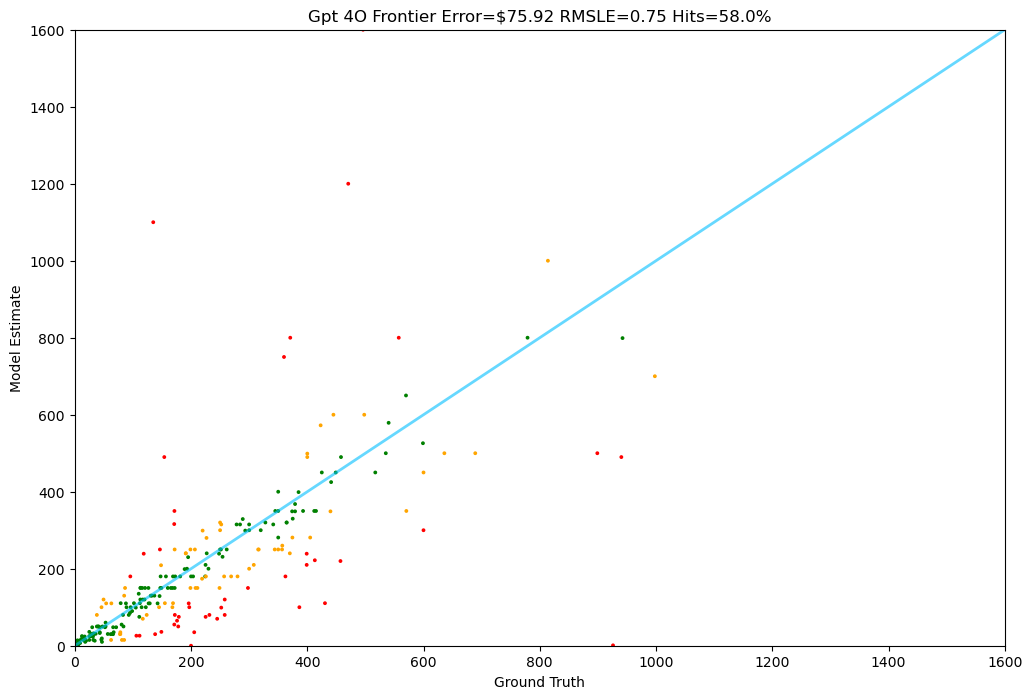
GPT-4o
OpenAI's most capable model performs well but at significantly higher computational cost.
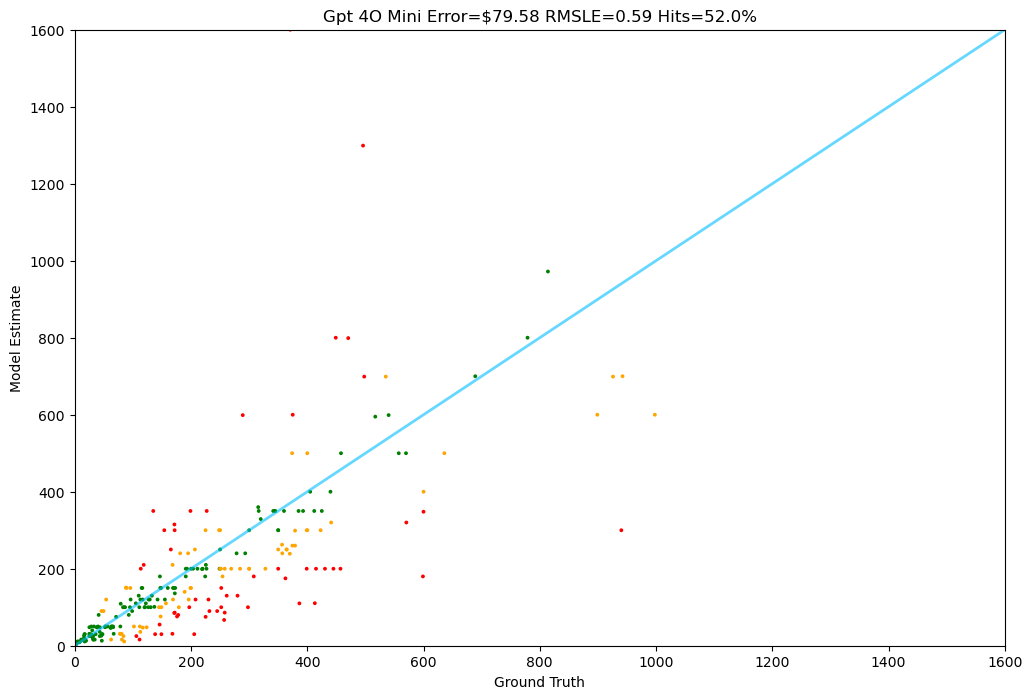
GPT-4 Mini
OpenAI's efficient model offers good performance but still trails our specialized approach.
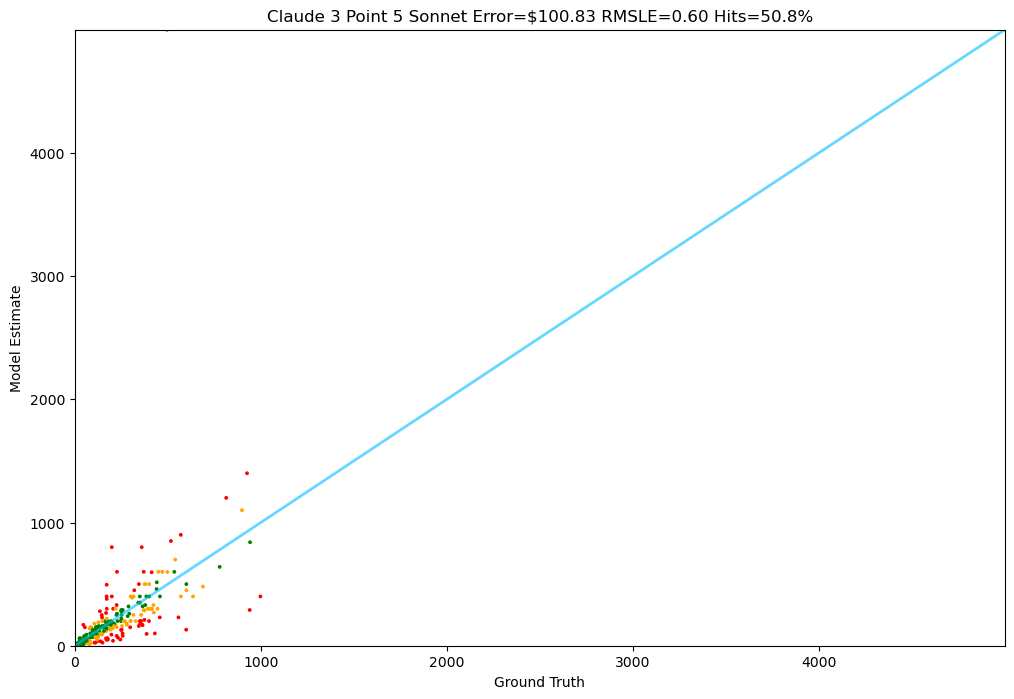
Claude 3.5 Sonnet
Anthropic's advanced model shows decent performance but higher error rates.
🔬 Traditional Machine Learning Methods
Comparison with classical ML approaches highlights the advantage of specialized LLM training:
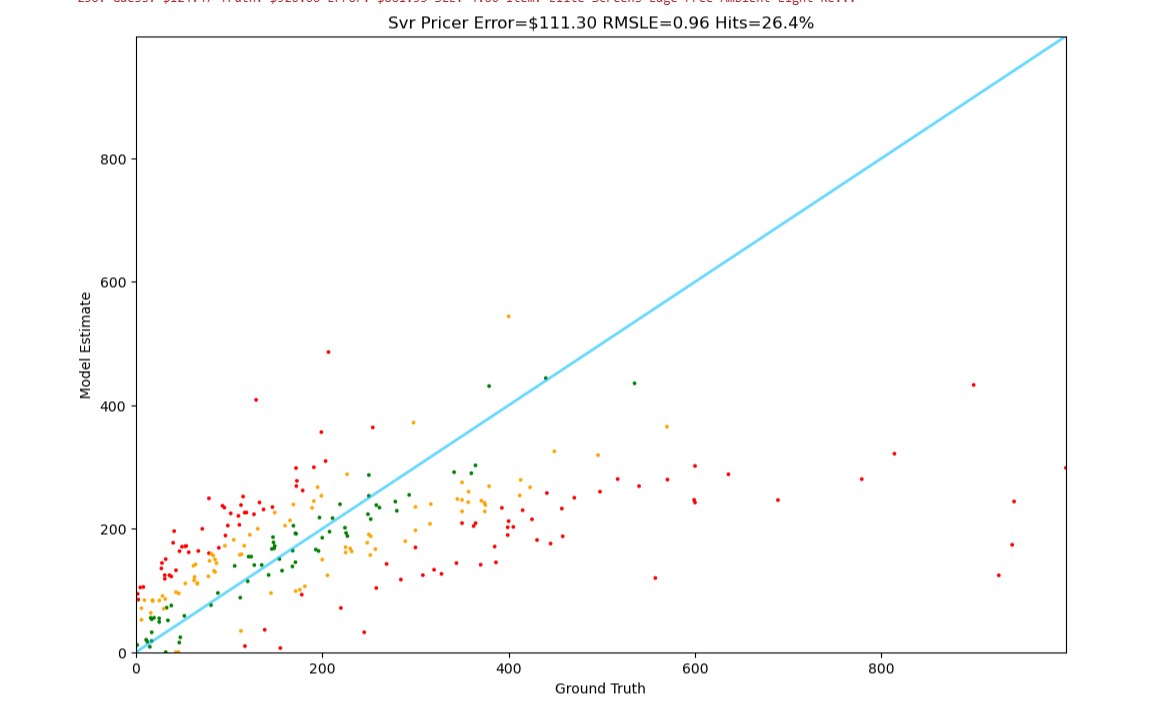
Support Vector Regression
Traditional ML approach with reasonable performance but limited understanding of product context.
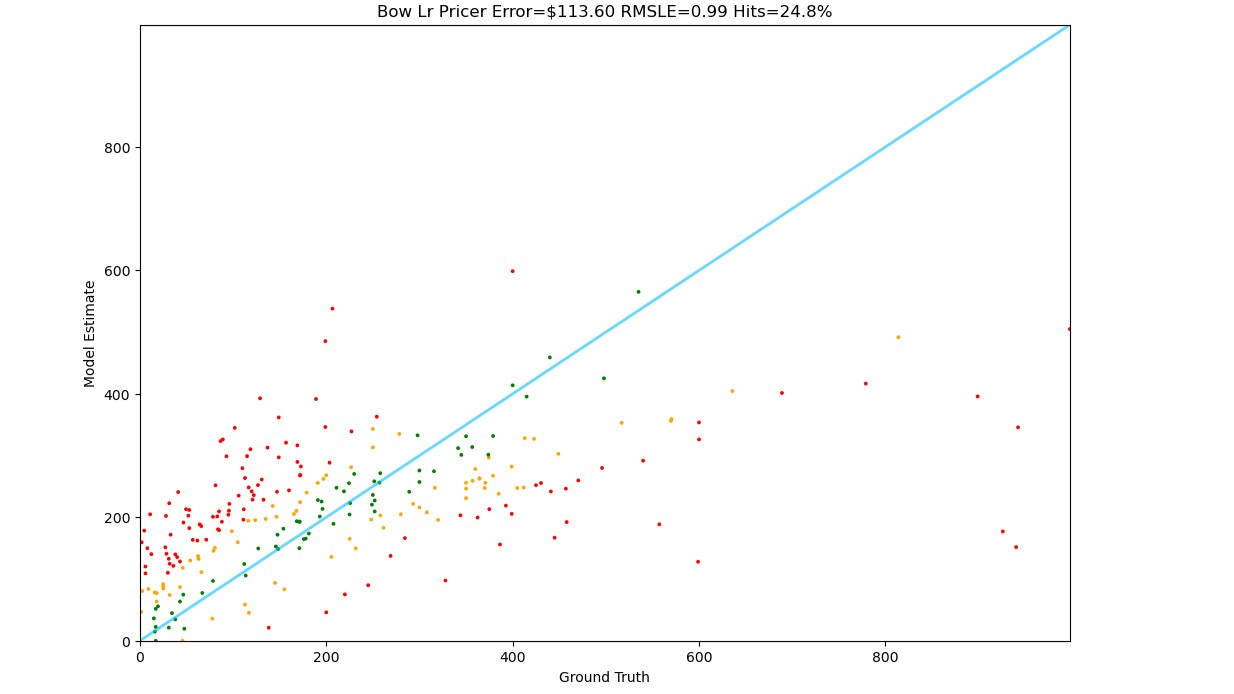
Bag of Words + Linear Regression
Simple text representation approach lacks semantic understanding of product features.
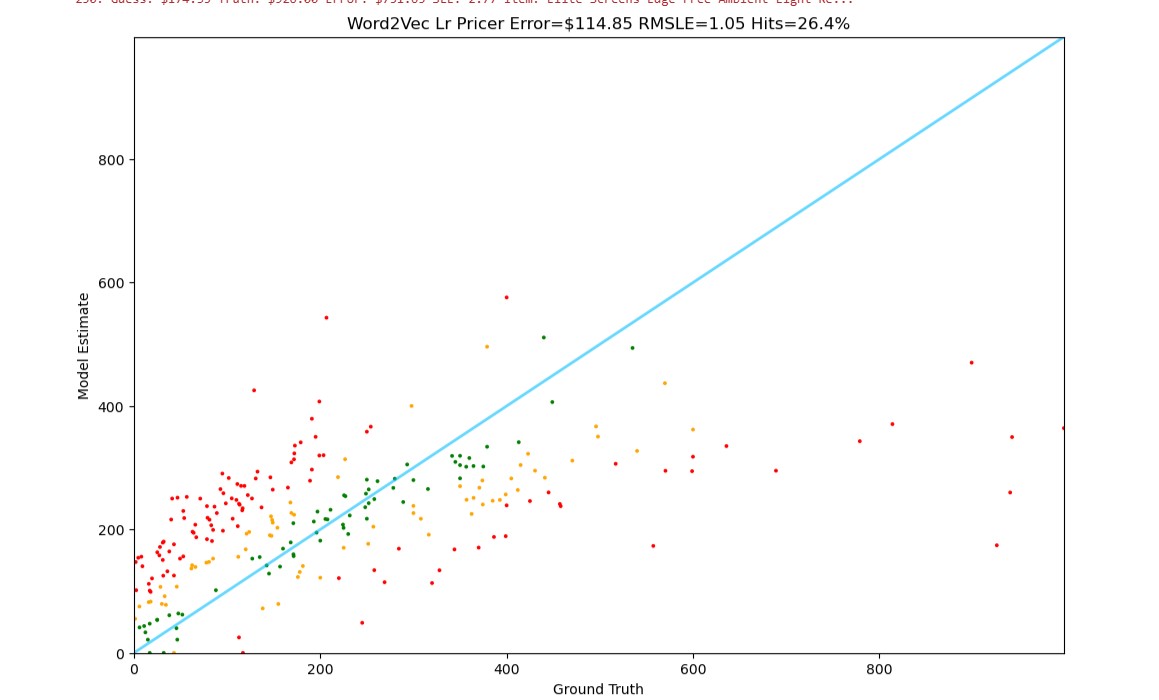
Word2Vec + Linear Regression
Word embeddings provide better representation but still fall short of modern approaches.
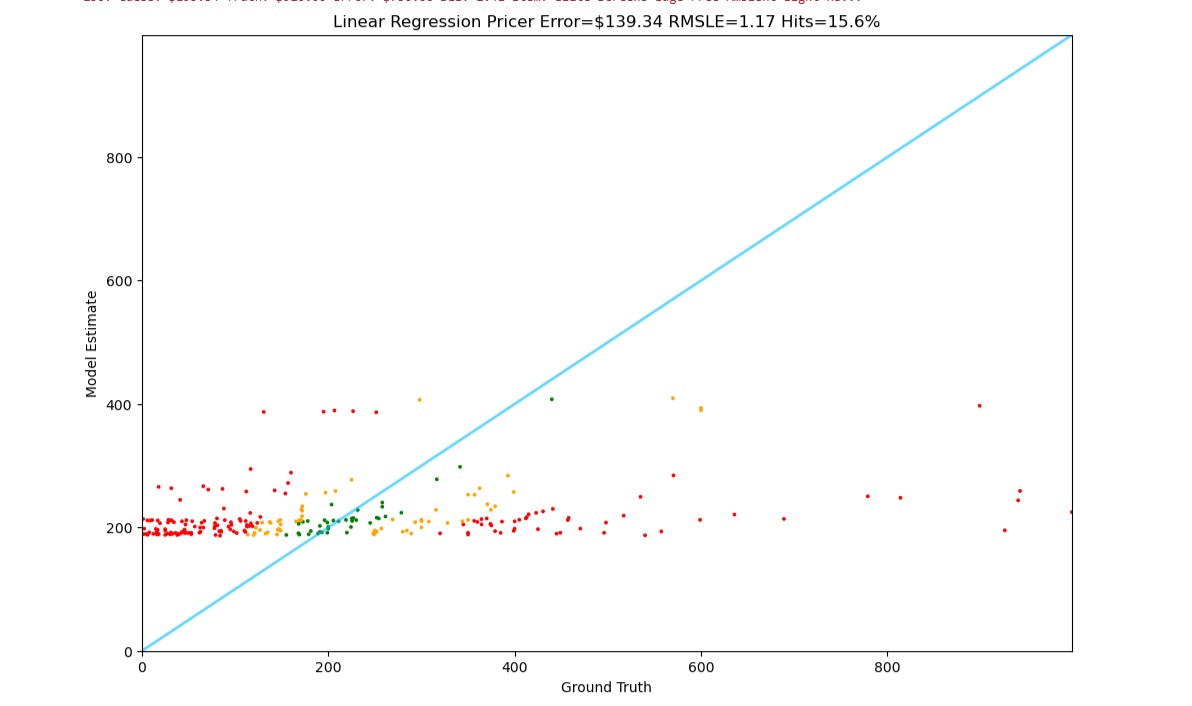
Linear Regression (Basic Features)
Basic statistical approach with handcrafted features shows significant limitations.
📈 Baseline Comparisons
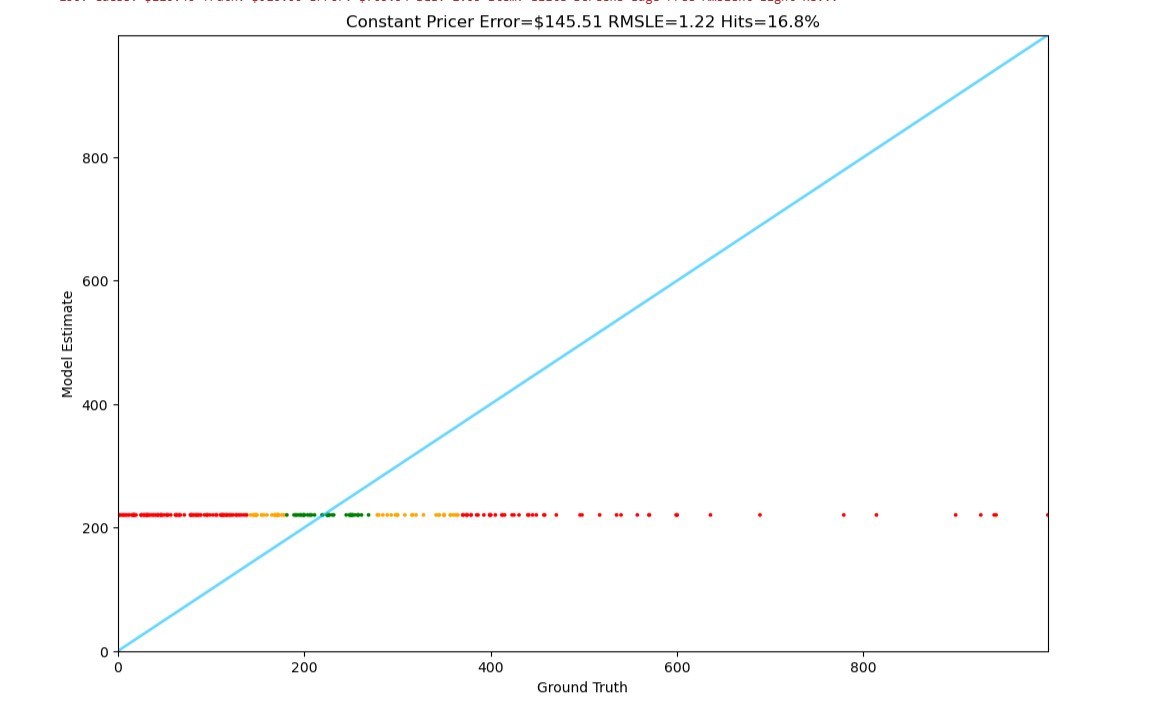
Random Price Assignment
Baseline random approach demonstrates the value of intelligent pricing models.
🎯 Key Insights
- Superior Performance: PriceBench achieves the lowest error rate ($71.65) among all tested approaches
- Cost Effectiveness: Outperforms expensive frontier models like GPT-4o while being significantly more economical
- Specialized Training: Fine-tuning on domain-specific data provides substantial advantages over general-purpose models
- Semantic Understanding: Modern LLM approaches dramatically outperform traditional ML methods
- Practical Viability: 2x better than traditional ML approaches and competitive with $20+ per 1M token models
💡 The PriceBench Advantage
By combining specialized training data, efficient QLoRA fine-tuning, and the powerful Meta-Llama-3.1-8B foundation, PriceBench delivers:
Lowest error rate across all models tested
Fraction of the cost of frontier AI models
Quick predictions suitable for real-time applications
Purpose-built for pricing tasks
👋 About Me
Hi there! I'm Sushant Nagi, a passionate developer who loves creating intelligent, scalable applications that push the boundaries of what's possible with modern technology.
🌐 Portfolio
Check out my interactive 3D portfolio at sushantium.space
Note: It's a 3D experience, so it might take a minute to load properly—but trust me, it's worth the wait! 🚀
🛠️ Tech Stack
I specialize in building intelligent, scalable applications using a diverse range of technologies:
- Core Languages: Python, JavaScript, HTML, CSS
- Backend: FastAPI, PostgreSQL, SQLite
- Frontend: ReactJS, ThreeJS, Tailwind CSS
- AI & Data: LLM Engineering, Data Science, Machine Learning
- Cloud & DevOps: Azure, VPS, Linux/Ubuntu Systems
- Additional: OAuth, Web Scraping, Database Management
I blend full-stack development with AI-powered creativity to create solutions that are both technically robust and user-friendly.
📧 Contact Me
I'm always excited to connect with fellow developers, potential collaborators, or anyone interested in AI and technology!
Let's build something amazing together! Whether you want to discuss AI, collaborate on a project, or just say hi, I'd love to hear from you. 🌟